기술이 발전하면서 인터넷은 곳곳에서 쓰이게 되었다.
와중에 많은 문제가 발생하고 해결되었는데 아직도 해결중인 문제는 데이터 전송 속도를 올리는 일이다.
더 많은 데이터를 손실 없이 빠르게 전송하는 일은 인터넷의 역사와 같이 발전해왔다.
현 시점에서 가장 현대적인 해결책이 바로 graphQL이다.
graphQL 이란?
graphQL은 API용 query 언어이자 data를 가져오기 위한 query를 수행하는 runtime을 말한다.
이름에서 느껴지듯 Graph Query Language의 약자이자 SQL과 마찬가지로 query 언어이다.
예시
여기선 graphQL이 어떻게 생겼는지 맛만 보자.
graphQL에서의 query는 다음과 같다.
sql의 query 처럼 필요한 값들을 query해 올 수 있다.
{
hero {
name
height
mass
}
}
그렇다면, 응답은
{
"hero": {
"name": "Luke Skywalker",
"height": 1.72,
"mass": 77
}
}
mass 값이 필요하지 않은 경우
{
hero {
name
height
}
}
그렇다면, 응답은
{
"hero": {
"name": "Luke Skywalker",
"height": 1.72
}
}
graphQL의 탄생
facebook에서는 RESTful 서버를 사용하고 있었는데 당시 성능도 별로였고 앱에서의 충돌도 잦았다.
이 때 개발자들이 데이터 전송 방식을 개선해야 한다는 것을 깨닫고 데이터를 다른 시각을 바라보기 시작하면서 탄생한 것이 facebook의 client 및 server의 data model 요구사항과 기능을 정립하기 위한 query 언어였다.
2015년 graphQL의 초기 명세가 나왔고, 현재 facebook은 내부의 data fetch는 대부분 graphQL로 이루어지고 있다고 한다.
이렇게 탄생한 것이 여러 다발의 데이터 전송을 graph로 묶어 request 수를 줄이고 효율성을 확보하여 문제를 해결하는 목적을 가진 graphQL이다.
예시
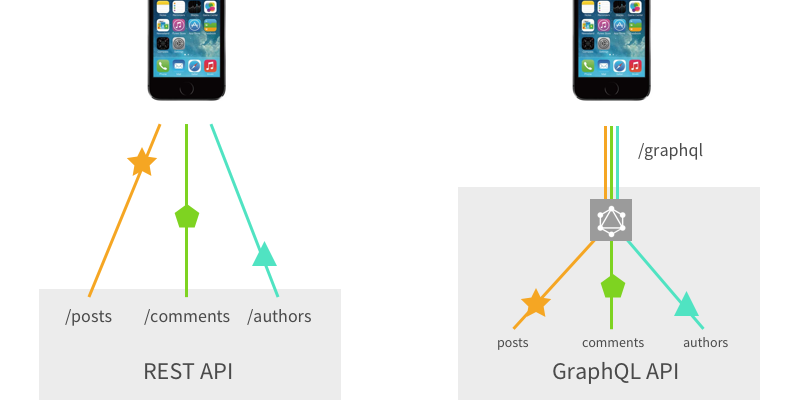
REST는 각각의 container에 대해 call을 요청한다.
- posts, comments, authors
GraphGL은 graph를 만들어서 필요한 모든 값들을 한 번에 요청한다.
REST의 단점
현재의 데이터 전송 방식은 RPC, SOAP를 거쳐 REST를 정석처럼 사용하는 분위기다.
- 내가 서비스하는 서버도 REST를 사용하고 있기도 하고.
당연히 GraphQL이 탄생하는데는 위에서 말했듯 REST의 단점이 보였기 때문이다. REST의 단점을 명확히 짚어보면 graphQL의 장점이 또렷하게 보인다.
Over Fetching
Over Fetch는 RESTful API를 디자인하면 전형적으로 만나볼 수 있는 rest의 단점이다.
나는 이게 되게 불필요하고 손해가 있는 작업이라고 생각하면서도 이걸 바꿀 수 있다는 생각을 못했던 것 같다.
예시
github의 REST api를 호출해보자.
{
"login": "meansoup",
"id": 24368552,
"node_id": "MDQ6VXNlcjI0MzY4NTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/24368552?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meansoup",
"html_url": "https://github.com/meansoup",
"followers_url": "https://api.github.com/users/meansoup/followers",
"following_url": "https://api.github.com/users/meansoup/following{/other_user}",
"gists_url": "https://api.github.com/users/meansoup/gists{/gist_id}",
...
}
문제는, 만약 내가 만들 서비스가 여기서 id와 avatar_url, url 세 가지 값만 필요한 경우에 발생한다.
- 내가 구현한 client는 필요없는 전체 데이터를 모두 받아야 한다.
- github server도 필요없는 데이터를 내려주기 위해 네트워크를 낭비해야 한다.
RESTful api server를 운영해본 개발자라면 공감하겠지만, 사실 대부분의 api에서 over fetch는 굉장히 쉽게 자주 발생한다.
under fetching
그렇다면 under fetch는 뭘까?
fetching을 하고 추가 데이터를 또 다시 요청해야 하는 상황을 말한다.
예시
이번엔 github의 followers api를 호출해보자.
[
{
"login": "chanhyeong",
"id": 10507662,
"node_id": "MDQ6VXNlcjEwNTA3NjYy",
"avatar_url": "https://avatars.githubusercontent.com/u/10507662?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chanhyeong",
"html_url": "https://github.com/chanhyeong",
"followers_url": "https://api.github.com/users/chanhyeong/followers",
"following_url": "https://api.github.com/users/chanhyeong/following{/other_user}",
"gists_url": "https://api.github.com/users/chanhyeong/gists{/gist_id}",
...
}
...
}
나는 이번엔 follower들의 정보를 얻어와서 서비스를 만들려고 한다.
- followers 요청을 하고 나온 user들을 가지고 다시 user 정보를 요청해야 한다.
- curl https://api.github.com/users/follower1
- curl https://api.github.com/users/follower2
- curl https://api.github.com/users/follower3
- curl https://api.github.com/users/follower4
- follower가 많아질 경우 내 call은 n 번이나 증가하게 된다.
- 증가되는 call 만큼 resource를 사용하고 데이터는 매번 over fetching되며 응답 시간은 늘어진다.
under fetching도 쉽게 자주 볼 수 있다.
folder 안에 있는 item들을 반환하거나, post의 comment에서도 볼 수 있고.
under fetching의 주요 문제는 응답 시간을 늘어지게 하는 api call 수의 증가이고, 이는 graphQL에서 굉장히 효과적으로 처리할 수 있다.
endpoint 관리
REST API의 단점은 유연성이 부족하다는 것이다.
client에서 변경사항이 생기면 endpoint를 새로 만들어야 하고, 이렇게 되면 endpoint의 수가 몇 배로 늘어나기도 한다.
- 우리 서비스는 v1 api, v2 api로 버전업을 하면서 제공하는 편.
이렇게 되면 개발 속도가 느려진다.
새로운 endpoint를 만들기 위해 client & server 팀이 협업을 해야하고, 추후 보수 작업에서도 endpoint에 따른 작업이 많아지기 때문이다.
- graphQL은 단일 endpoint를 사용하여 이런 문제점에서 자유롭다.
reference
웹 앱 API 개발을 위한 GraphQL, Eve Porcello / Alex Banks
https://graphql.org/
https://tech.kakao.com/2019/08/01/graphql-basic/
https://www.apollographql.com/blog/graphql/basics/graphql-vs-rest/