스프링에서 ORMs 개념을 적용한 표준이 JpaRepository이다.
JpaRepository와 CrudRepository의 개념을 명확하게 모르고 사용해왔는데 차이를 정리해본다.
구조
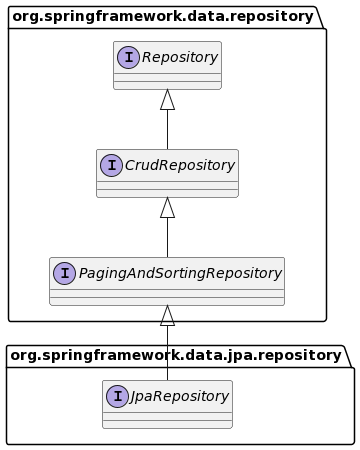
우선 위와 같이 상속 구조를 갖는다.
CrudRepository
기본적인 CRUD 기능을 제공한다.
- Create, Read, Update, Delete
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}
PagingAndSortingRepository
pagination과 sorting을 제공한다.
- pagination할 때 Pageable은 page size, current page number, sorting을 포함해야 한다.
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort var1);
Page<T> findAll(Pageable var1);
}
JpaRepository
flushing the persistence context과 delete records in a batch 같은 JPA와 관련된 기능을 제공한다.
flush()는 database에 entity의 save 요청을 바로 밀어넣는 것을 의미한다.
flush가 없다면 save() 요청은 persistence context에 남아있다가 flush()나 commit()이 들어오면 database에 밀어 넣는다.
- JPA에서 성능상 최적화되게 flush를 하기 때문에 일반적으로 flush를 사용하는 일은 없다.
- 성능 저하가 올 수 있다.
deleteBatch는 대량의 삭제를 의미한다.
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
T getById(ID id);
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
당연히 상속 때문에 JpaRepository는 모든 기능을 제공한다.
따라서 기능이 필요하지 않은 경우에만 상위 repository를 사용하면 된다.
@NoRepositoryBean
repository 마다 붙어있는 @NoRepositoryBean은 뭘까?
실제 entity의 repository로 사용하지 않을 interface 역할을 하는 repository들이 instance로 생성되는 것을 제외하기 위한 annotation이다.
예시
stackoverflow의 답변의 예시를 가져왔다.
public interface com.foobar.MyBaseInterface<…,…> extends CrudRepository<…,…> {
void foo();
}
public interface com.foobar.CustomerRepository extends MyBaseInterface<Customer, Long> {
}
위와 같은 코드에서 @EnableJpaRepositories(basePackages = {"com.foobar"})으로 jpa repository를 등록한 것이다.
이렇게 있을 때 @NoRepositoryBean가 명시되지 않는다면 spring은 MyBaseInterface가 실제 사용할 repository 구현체가 아니라는 것을 알 수 없다.
그러면 CustomerRepository을 생성하는데 실패한다.
이런 문제를 해결하기 위해 @NoRepositoryBean를 사용한다.
reference
- https://www.baeldung.com/spring-data-repositories
- https://stackoverflow.com/questions/14014086/what-is-difference-between-crudrepository-and-jparepository-interfaces-in-spring
-
https://www.baeldung.com/spring-data-jpa-save-saveandflush
- https://stackoverflow.com/questions/11576831/-understanding-the-spring-data-jpa-norepositorybean-interface
- https://docs.spring.io/spring-data/commons/docs/current/api/org/springframework/data/repository/NoRepositoryBean.html