dynamodb에서는 RDB를 사용하듯이 table을 많이 사용하는 것을 권장하지 않는다.
AWS에서 성능과 비용 개선을 위해 가이드를 자주 하기도 한다.
최근 single table에 대한 이점을 다시 돌아볼 기회가 있어서 정리해본다.
relational design
기존의 관계형 DB에서는 일반적으로 여러 table을 두고 사용한다.
각 table은 다른 table의 foreign key를 갖고, multiple tables에서 join query로 마치 single-table-view를 생성해서 사용한다.
이런 query는 편리하고 유연하지만, DB 내부에선 굉장히 비싼 operation이고 horiziontal scale out이 어렵다.
dynamodb design
RDB에서는 scale의 한계가 있지만 dynamodb에서는 scale의 한계가 없다.
이건 SQL과 NoSQL의 차이1이다.
dynamodb의 중요한 goal 중 하나인데, scale이 증가하더라도 예측 가능한 performance를 제공할 수 있도록 디자인 한다는 것.
그래서 dynamodb는 scale 할 수 없는 operation 들을 제공하지 않고 있고, join도 그렇다.
single-table
join은 할 수 없으나 join 처럼 하나의 query로 data를 가져오기 위한 방법이 있는데 이게 바로 single-table design이다.
single-table design에서는 여러 data type들을 하나의 table에 저장하고 client에서 한 번에 query를 해가는 방식이다.
장/단점과 예시를 보자.
single-table 장점
join과 유사하게 하나의 query로 data를 가져온다.
위에서 말했듯 하나의 query로 data를 가져올 수 있다.
query의 개수가 줄어드는 것은 RTT 감소로 인한 성능 개선과 비용 감소로 이어진다.
여러 table을 사용하지 않아서 monitoring/alert 포인트를 줄일 수 있다.
aws에서 dynamodb를 소개할 때 DBA가 필요하지 않은 서비스라고 소개했다.
그만큼 dynamodb는 돈만내면 참 편하게 쓸 수 있는 DB이다.
db의 throttling이나 RCU/WCU에 대한 관리가 여러 db를 모니터링 하지 않아도 되기 때문에 개발팀 입장에서 일이 많이 줄어든다.
비용을 절약할 수 있다.
2번과 이어지는 내용이다.
dynamo의 RCU/WCU에는 두 가지 과금 정책이 있는데 ondemand와 provisioned 이다.
- ondemand: 쓰는만큼 돈을 내기
- provisioned: provision을 설정하고 그 만큼 돈을 내기
ondemand가 더 싸보이지만 enterprise 급에서는 대부분 provisioned를 사용한다.
대체적으로 두 가지 이유 때문이다.
- 급격한 db 요청이 몰릴 때, ondemand에서 RCU/WCU를 늘리더라도 시간이 걸리고 그 사이에 장애가 발생한다. (물론 빨리 늘지만 그래도 시간이 걸린다)
- provisioned로 계약하면 ondemand 보다 가격이 저렴하다.
provision는 당연히 서비스에서 사용되는 수치보다 한참 넉넉하게 설정하는 편이다.
10개의 table에 대해 provision이 여유롭게 설정된 것과, 1개의 table로 합쳐서 여유롭게 설정되는 차이에서 비용 절약이 발생한다.
single-table 단점
single-table을 설계하기 위해 학습곡선이 있다.
primaryKey, sortKey에 대한 개념.
key 중복이 없도록 data 설계.
GSI와 LSI.
등에 대해 알고 배워야 한다.
join은 정답같은 query가 있다고 한다면 dynamo table design은 설계하는 사람마다 다 다르기 때문에 더 어렵기도 하다.
근데 단점에 학습곡선을 넣는건 단점이 별로 없다는 얘기가 아닐까 싶다. 배우는건 당연하지.
새로운 access pattern을 추가하기 어렵다.
RDB의 table join 같은 경우는 table이 추가되고 새로운 query가 필요할 때 join을 다시 짜면 된다.
그런데 single table에서는 primary key & sort key가 query를 한 번에 해오는데 중요한 요소가 되기 때문에 새로운 pattern이 필요할 때 key 설계가 변경되어야 하는 경우가 있다.
그래서 dynamodb 설계는 application의 access pattern, usecase 들을 정리하는 것부터 시작한다.
data dump가 어렵다.
블로그를 예로 들면, 유저와 포스트와 코멘트가 한 테이블에 있는 것이기 때문에 유저 dump가 필요한 경우 쉽지 않다.
single table 예시

db entity의 구조가 위와 같다고 하자.
전통적으로는 아래와 같은 RDB table들을 설계할 수 있다.
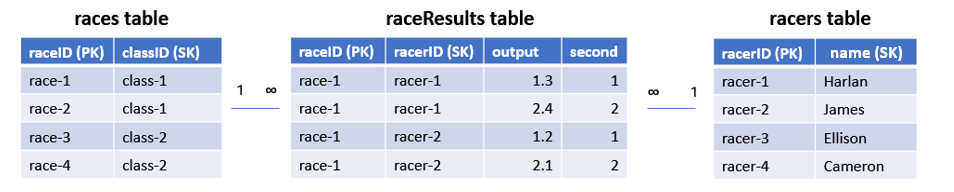
single table에서는 아래와 같이 table을 설계한다.
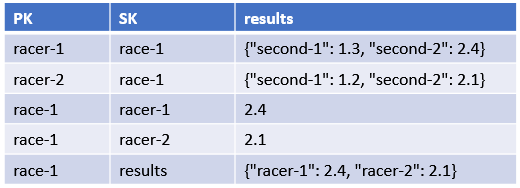
요구사항에 따라 primary key, sort key에 맞게 entity를 구분해서 넣는다.
참고사항
- 모든 데이터를 하나의 테이블에 넣는다. 그게 안되면 가능한 적은 테이블을 사용한다.
- PK, SK, GS1PK 같은 key name을 맞춘다.
- entity의 type을 파악할 수 있도록 attribute를 추가하면 좋다.
- single table 적용 후기
reference
- https://aws.amazon.com/blogs/compute/creating-a-single-table-design-with-amazon-dynamodb/
- https://www.alexdebrie.com/posts/dynamodb-single-table/
- https://medium.com/till-engineering/single-table-design-aws-dynamodb-cffd230a371f
-
SQL은 기본적으로 scale up, NoSQL은 scale out으로 확장한다. SQL vs NoSQL 참고 ↩