DDD tactical components
에그리게잇은 모든 DDD의 전술적인 지침 중에서도 무엇보다 정확히 규명되지 않은 패턴 중 하나다. - Vaughn Vernon
aggregate?
에그리게잇이란 단지 공통 부모 아래 긴밀하게 연결된 객체의 그래프를 묶는 방법 중 하나가 아니다.
이런 생각들로 잘못 모델링 된 aggregate들이 생겨난다.
- 컴포지션의 편의에 맞춰 설계해서 에그리게잇을 너무 크게 만들어버리는 경우
- 너무 걷어내서 고정자를 보호하지 못하는 에그리게잇을 만드는 경우
큰 aggregate
A는 ~를 포함한다. 에 중점을 두고 aggregate을 설계한다면 큰 aggregate을 만들기 쉽다.
옳지 않다.
장점:
- A에 포함된 모델들의 변경에 따라 모든 부분을 보호하기 위해 이런 설계를 할 수 있다.
- A를 내부의 객체들을 포함한 아주 큰 aggregate으로 모델링하면 의도치 않은 client가 누락되지 않도록 보호할 수 있다.
단점:
- 크기가 큰 에그리게잇은 처음엔 그럴싸해 보였지만 실제로 실용적이진 않다.
- 에그리게잇의 단위가 크기 때문에 트랜잭션이 실패하기 쉽다.
다수의 aggregate
동시성 문제를 해결하기 위해 아래와 같은 구조를 사용하기도 한다. 이런 구조는 aggregate의 invirant를 동시에 발생하는 변경으로부터 보호할 수 있다.
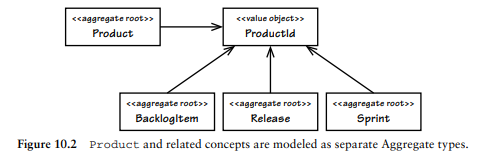
장점:
- 트랜잭션에 이점이 있다. 성공하기 쉽다.
- 다른 aggregate 인스턴스들을 동시에 안전하게 생성할 수 있다.
단점:
- 클라이언트가 사용하는 관점에서 여러 개의 작은 aggregate은 불편할 수 있다.
큰 aggregate vs 다수 aggregate
- 큰 에그리게잇은 에그리게잇 내부에서 모두 수행하는 (return void) CQS command로 수행되고
- 다수 에그리게잇은 각 메소드가 새로운 에그리게잇 인스턴스를 반환하는 (return Aggregate
) CQS query로 수행된다
다수의 aggregate 모델링에서는 다른 aggregate에 대해서 얼마든지 동시에 생성할 수 있다.
- 트랜잭션에 이점이 있다. 큰 aggregate에서 문제가 되는 부분.
- 클라이언트가 사용하는 관점에서 여러 개의 작은 에그리게잇은 불편할 수 있다.
모델링 규칙
invirant
invirant는 aggregate의 모델링 규칙을 설명할 때 가장 중요한 개념으로 ![]()
언제나 일관성을 유지해야 한다는 비즈니스 규칙이다.
예시
- c = a + b
- a = 2
- b = 3
같은 조건 이 있을 때 c가 5가 아닌 경우는 시스템의 invirant를 위반하는 것이다.
c가 일관성을 갖게 하기 위해 모델의 특성을 둘러싸는 경계를 설계해야 한다.
그렇다면 a, b, c는 하나의 aggregate에 속하게 되는 것.
예시
- c = a + b
- a = 2
- b = 3
- d + e = 5
같은 조건 이 있을 때 c가 5가 아닌 경우는 시스템의 invirant를 위반하는 것이다. c가 일관성을 갖게 하기 위해 모델의 특성을 둘러싸는 경계를 설계해야 한다. 그렇다면 a, b, c는 하나의 aggregate에 속하게 되는 것.
여기에 마지막 조건이 추가된다고 보자. a, b, c는 하나의 aggregate이겠지만, d, e는 관련이 없는 다른 aggregate이 될 것이다.
진짜 invirant를 일관성 경계 안에서 모델링하라
가장 먼저 invirant를 소개한 것은 bounded context에서 aggregate을 찾으려면 모델의 진짜 invirant를 이해해야 하기 때문이다.
invirant를 알아야 aggregate으로 묶어야 할 객체가 무엇인지 결정할 수 있다.
일관성 경계는 어떤 요청이 수행되든 경계 안의 모든 대상이 invirant에 대한 비즈니스 규칙들을 준수하도록 논리적으로 보장해야 한다.
이 경계 밖의 일관성은 aggregate과 무관하다.
그러므로 aggregate은 트랜잭션의 일관성 경계와 같은 개념이다.
올바르게 설계된 aggregate은 단일 트랜잭션 내에서 완벽한 일관성을 유지하면서 비즈니스 요구사항과 그 invirant에 맞춰 수정되어야 한다.
또 하나의 트랙잭션당 하나의 aggregate만 수정되어야 한다.
- 경험적으로 얻어진 aggregate을 사용하는 가장 중요한 이유라고
작은 aggregate으로 설계하라
모든 트랜잭션이 성공하는 경우에도 큰 aggregate을 사용하는 것은 성능과 확장성에 문제가 있다.
- 데이터가 많이 쌓인 상황에서 데이터를 추가하고 싶을 때도 한 번에 가져오는 데이터의 크기가 너무 많다.
- 이를 막기 위해 지연로딩을 하기도 하지만 지연로딩으로도 해결할 수 없는 경우가 있다.
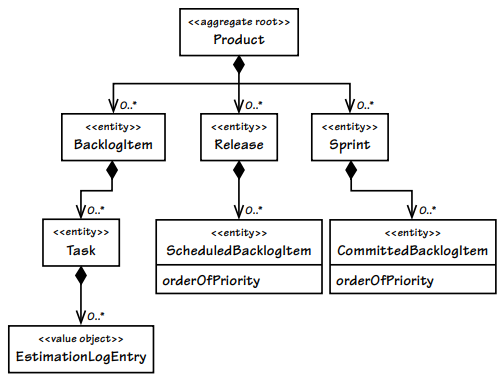
다이어그램의 0 ... * 에 속으면 안된다 0이 되는 경우는 거의 없고 대부분은 시간이 지나면 계속 증가한다.
결국 큰 aggregate은 시간이 흐를수록 더 나빠진다.
위 예제를 보면 거짓 invirant와 컴포지션적 편의성이 설계를 주도했기 때문에 시작부터 문제가 있었다.
트랜잭션의 성공적인 종료, 성능, 확장성에 안좋은 영향을 미쳤다.
그럼 얼마나 작아야할까?
당연한 말이지만, 무작정 작지도 않고 너무 크지도 않게 필요한 만큼만 작아야 한다.
aggregate은 도메인 전문가가 규칙으로 구체화하지 않더라도 다른 대상과 일관성을 유지해야 한다.
예시
product가 name과 description을 갖는다면 name과 description이 일관성이 맞지 않는건 상상할 수 없다.
둘 중 하나를 바꾸고 다른 것을 그대로 두는 경우는 철자를 고치거나 description을 name에 맞게 바꾸는 정도일 것.
도메인 전문가가 비즈니스 규칙으로 명시하지 않더라도 여기에 비즈니스 규칙이 녹아있는 것.
예시
Qi4j를 사용한 한 프로젝트에서 니클라스 헤드만의 팀은 aggregate을 설계할 때 70 퍼센트는 단일 엔티티와 vo의 aggregate으로 설계하고 남은 30 퍼센트는 두 세개의 엔티티가 필요했다고 한다.
대부분 이런 것은 아니지만 높은 비율로 aggregate 루트 엔티티를 하나로 구성할 수 있다.
최대한 나누는 방향을 고려하는데, 고려할 때 invirant를 확인한다.
예시
BacklogItem«Aggregate root»에 Task«Entity»가 있다
이 둘을 나눠야 하지는 않을지 고민해보고 그 기준으로 invirant가 있는지 확인한다.
크기가 작은 aggregate은 성능과 확장성이 좋고, 커밋을 가로막는 문제가 없어 트랜잭션 성공 가능성도 높다.
따라서 크기를 제한하는 편이 현명하다.
혹시 일관성 규칙이 꼭 필요한 상황에서는 엔티티나 컬렉션을 추가하고 그러면서도 전체 크기는 가능한 작게 유지하자.
유스케이스를 전부 믿지는 말기
도메인 전문가가 만든 유스케이스는 설계에 영항을 크게 미친다.
그러나 유스케이스는 개발자와 모델링 관점이 포함되지 않았다는 것을 생각하야 한다.
각 유스케이스와 현재의 모델은 조화를 이뤄야 하고 여기엔 aggregate에 대한 결정도 포함된다.
특정 유스케이스 때문에 여러 aggregate를 수정해야 한다면 유스케이스의 진짜 목적이 여러 트랜잭션에 있는지 하나의 트랜잭션 안에서 이뤄지는지 반드시 확인해야 한다. 여러 aggregate을 수정하는 것이 하나의 트랜잭션에서 필요하다면 잘 작성된 유스케이스라고 해도 진짜 aggregate을 정확히 반영하지 못할 수 있다.
- 유스케이스가 무조건 하나의 트랜잭션에서 이뤄져야하는 것은 아니다. 여러 트랜잭션일 수 있다. 단순히 여러 aggregate 인스턴스가 하나의 트랜잭션에서 수정되는 것만 막으면 된다.
하나의 트랜잭션에서 일관성을 유지해주길 기대하는 유스케이스가 있다고 해서 반드시 지켜야하는 것은 아니다. 이런 경우 대부분 aggregate 사이의 결과적 일관성을 통해 비즈니스 목표를 달성할 수 있다.
유스케이스를 그대로 따르기만 하면 통제하기 힘든 설계로 이어질 수 있다. 유스케이스를 그냥 따르는 것이 아니라 비판적으로 살펴보고 면밀히 확인해야 한다. 필요에 따라다시 유스케이스를 써야할 수도 있다.
ID로 다른 aggregate을 참조하라
aggregate을 설계하면서 객체 그래프를 깊이 탐색하는 컴포지션 구조를 설계할 수도 있지만 이는 aggregate에 맞지 않는다. aggregate은 다른 aggregate 루트로의 참조를 가질 수 있다. 그렇지만 이는 참조된 aggregate을 참조하고 있는 aggregate의 일관성 경계 안쪽에 위치시킨다는 의미가 아니다.
aggregate을 가지고 있는 경우
public class BacklogItem extends ConcurrencySafeEntity {
private Product product;
}
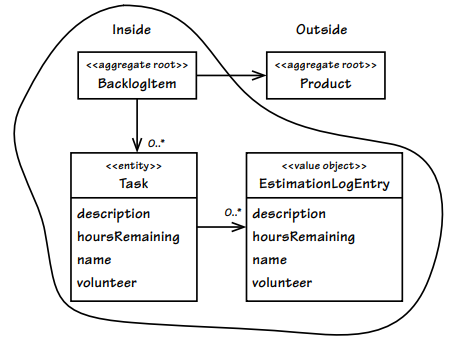
이런 구조는 좋지 않지만 이런 구조를 갖는 경우 고려해야할 것들이 있다.
- 참조하는 aggregate과 참조된 aggregate이 하나의 트랜잭션 안에서 수정되면 안된다.
- 하나의 트랜잭션에서 여러 인스턴스를 수정하고 있다면 일관성 경계가 잘못되었을 경우가 많다.
- 2번과 유사하게 수정이 묶여있는 aggregate에 영향을 미친다면 원자적 일관성 대신 결과적 일관성을 사용해야 한다는 표시일 수 있다.
객체 참조가 아닌 ID를 참조함으로서 이런 상황을 완전히 피할 수 있다.
참조(Id)를 가지고 있는 경우
public class BacklogItem extends ConcurrencySafeEntity {
private ProductId productId;
}
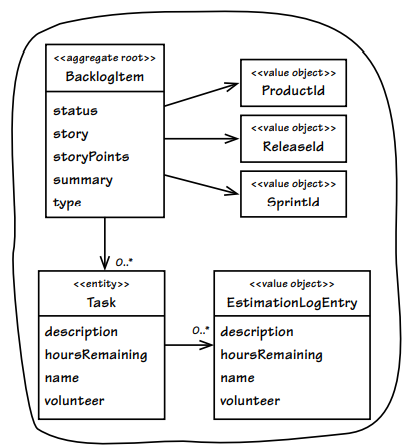
- 참조를 즉시 가져올 필요가 없기 때문에 작아진다.
- 인스턴스를 가져올 때 elapsed가 짧고 메모리가 적게 필요하기 때문에 모델의 성능도 개선된다.
- 메모리 할당 비용과 GC에도 긍정적인 영향을 미친다.
- 그렇다고 모델을 전혀 탐색할 수 없는건 아니다.
- aggregate 내부에서 리파지토리를 사용하거나 aggregate 사용 전에 repository나 domain service를 통해 객체를 조회할 수 있다.
경계의 밖에서 결과적 일관성(Eventual Consistency)을 사용하라
하나의 aggregate 인스턴스에서 커맨드를 수행할 때 하나 이상의 aggregate에서 추가적인 비즈니스 규칙이 수행돼야 한다면 결과적 일관성을 사용하자.
큰 규모의, 트래픽이 많은 엔터프라이즈에서는 aggregate 인스턴스가 절대적이고 완전하게 일관성을 유지할 수 없다는 점을 받아들인다면, 결과적 일관성이 더 적은 인스턴스가 관련된 더 작은 규모에서도 의미있다는 사실을 좀 더 쉽게 이해할 수 있다.
한 인스턴스가 수정되고 관련된 다른 수정이 완료될 때까지 어느정도 시간 지연이 용납될 수 있는지 도메인 전문가에게 물어보자.
개발자들은 원자적 변경의 사고방식에 사로잡혀있기 마련이고 도메인 전문가는 지연된 일관성에 더 관대하다.
결과적 일관성을 지원하는 방법
- aggregate 함수가 하나 이상의 비동기 구독자에게 제때 전달되는 도메인 이벤트를 발행한다.
- 각각의 구독자가 다른 유형의 aggregate 인스턴스를 가져오고 그에 기반해 동작을 수행한다.
- 각 구독자는 분리된 트랜잭션 내에서 수행되며 트랜잭션당 하나의 인스턴스만 수정한다는 aggregate 규칙을 따른다.
public class BacklogItem extends ConcurrencySafeEntity {
// ...
public void commitTo(Sprint aSprint) {
// ...
DomainEventPublisher
.instance()
.publish(new BacklogItemCommitted(
this.tenantId(),
this.backlogItemId(),
this.sprintId()));
}
}
이렇게 domain event를 발행해서 다른 트랜잭션에서 다른 aggregate을 수정1하도록 한다.
결과적 일관성 사용 여부 결정하기
트랜잭션을 사용할지 결과적 일관성을 사용할지 결정하기 쉽지 않다.
에릭 에반스의 지침을 참고하면 도움이 된다.
- 일관성을 보장하는 주체가 유스케이스를 수행하는 사용자의 일이라면 트랜잭션을 통해 일관성을 보장하자.
- 일관성을 보장하는 주체가 다른 사용자나 시스템이라면 결과적 일관성을 선택하자.
규칙을 어기는 경우
충분한 이유가 있을 때만 규칙을 어겨야 한다. 경험에 의지해서 규칙을 지키지 않아야할 변명거리를 찾아선 안된다.
반버논이 얘기하는 규칙을 어길만한 사례들
1. 사용자 인터페이스의 편의
편의를 위해 사용자가 한 번에 여러 일의 공통 특성을 정의해 배치를 생성할 수 있도록 허용할 때도 있다.
2. 기술적 메커니즘의 부족
결과적 일관성을 위해 메시징이나 타이머, 백그라운드 쓰레드와 같은 추가적인 처리 기능이 필요할 수 있다. 이런 메커니즘을 전혀 제공하지 않고 있다면 큰 aggregate을 생성하는 방향으로 가게될 확률이 높고 aggregate을 변경하거나 하나의 트랜잭션에서 둘 이상의 aggregate을 수정해야할 수도 있다.
3. 글로벌 트랜잭션
two-phase commit transaction을 엄격하게 지켜야하는 경우도 고려가 필요하다. 그치만 꼭 바운디드 컨텍스트 내에서 다수의 aggregate 인스턴스를 한 번에 수정해야하지 않을수도 있다.
4. 쿼리 성능
다른 aggregate에 대해 직접 객체 참조를 유지하는 편이 최선일 때가 있다. 리파지토리의 쿼리 성능 문제를 해결하는데 사용될 수도 있다.
구현
그래서 어떻게 해야할까.
- 고유 ID와 root entity를 생성한다. 하나의 entity를 aggregate root로 모델링한다.
- 가능하면 aggregate 내부를 entity보다는 VO로 모델링한다. (entity/vo 참고)
- ‘데메테르의 법칙’과 ‘묻지 말고 시켜라’를 사용한다.
- 데메테르의 법칙: 서버의 구조를 클라이언트가 완벽하게 알지 못하고 인터페이스만 제공받는다.
- 묻지말고 시켜라: 클라이언트가 서버 객체의 일부를 요구해선 안되고 자신이 갖고 있는 상태에 기반해 결정하고 서버에게 무엇을 할지 시켜야 한다.
reference
- Implement Domain Driven Design (chapter5 Entity), Vaughn Vernon
-
domain event를 통해 side effect으로 발생한 aggregate의 transaction을 분리할 수 있다. domain event 참고 ↩